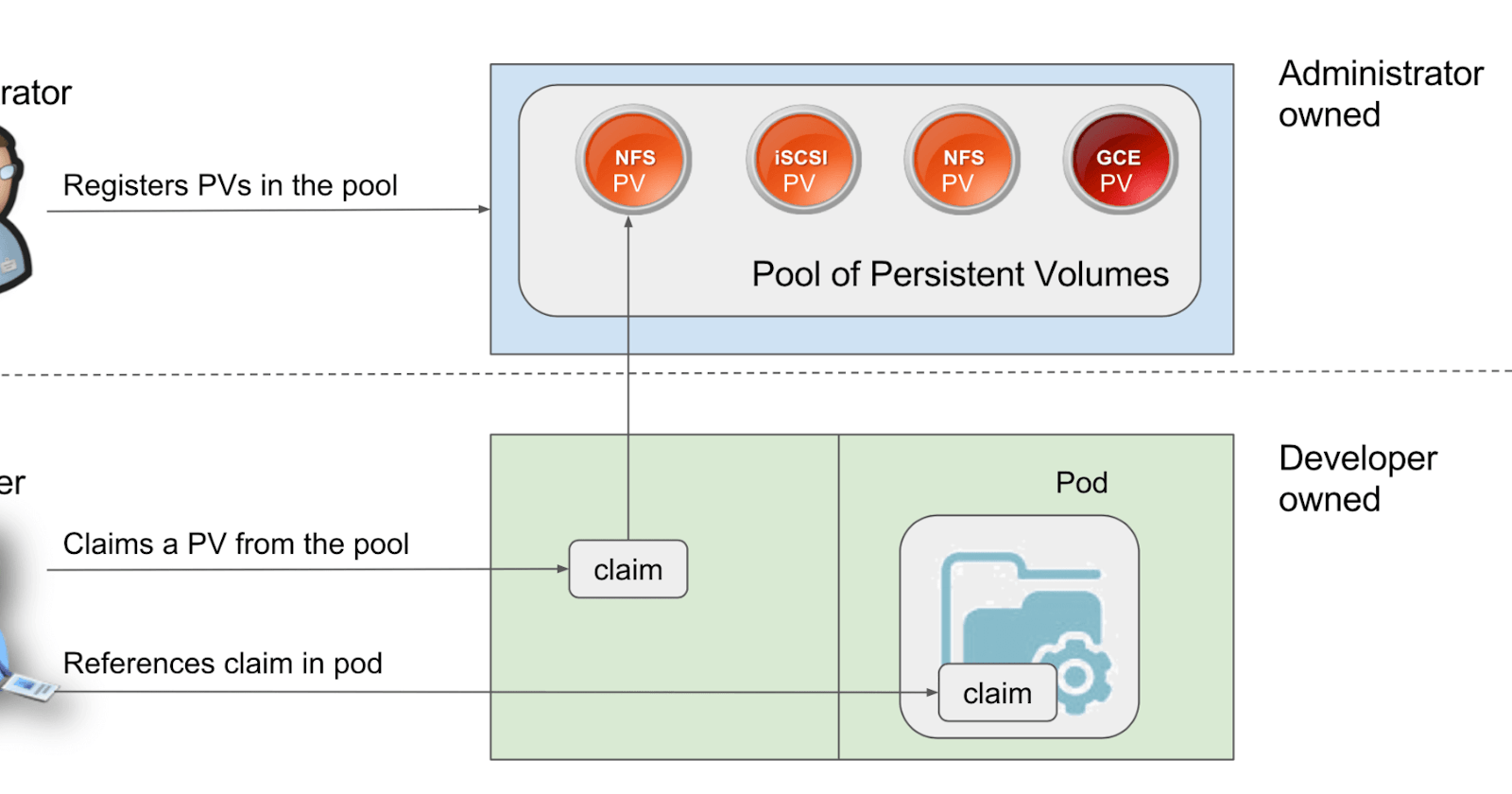


A persistent volume is a piece of storage in a cluster that an administrator has provisioned. It is a resource in the cluster, just as a node is a cluster resource. A persistent volume is a volume plug-in that has a lifecycle independent of any individual pod that uses the persistent volume. This API object captures details of implementation if the storage like NFS or a cloud-provider-specific storage system.
Why data persistence is important
Containers were developed to be stateless, ephemeral, lightweight tools, only megabytes in size, to speed application launch. However, this design is problematic when data needs to persist after the container goes away. And this problem increases as the scale of container management deployments with tools like Docker, Mesosphere, and Kubernetes grows.
Users are now executing hundreds (sometimes thousands) of nodes in clusters, making data management even more difficult given the unpredictable lifecycles of containers.
To ensure that data persists well beyond a container’s lifecycle, the best practice is to separate data management from containers. There are three approaches to data persistence in a container environment:
Storage plug-ins
Data volume containers
Building a local directory mount into the container as a data directory
Tools for persistent volumes and storage
Storage plug-ins. A storage plug-in is the most reliable and manageable option for persistent storage. A standard volume plug-in allows you to create, delete, and mount persistent volumes and to support commands from container management applications; Kubernetes offers such a plug-in. Many storage companies have also built incremental features into their container APIs to further simplify the container management process. These plug-ins offer capabilities such as managing and consuming volumes from any management host, consuming existing storage, or differentiating storage offerings with multiple instances.
Data volume containers. These containers let you manage data inside and between various containers. A data volume container doesn’t run an application; it serves as an entry point from which other containers can access the data volume. Data volumes can be shared among containers and can persist even after the container itself is deleted. Although setup of this method is relatively simple, ongoing management becomes complex. As containers are deleted, the data left behind can become orphaned, and it often is not cleaned up by the container manager. Because data volume containers can be directly accessed by the host, orphaned data can be garbage-collected as needed. But the process can lead data access privileges becoming corrupted, leaving potentially sensitive data vulnerable.
Directory mounts. These mounts tie the host to the container. The data structure is maintained from the host to the container, allowing persistence and reusability. Directory mounts can then be accessed to read and write, which also leaves security gaps. Because the directory mount can be given access to a host system’s directory, the container also holds the ability to delete or change content. This vulnerability means that not only could someone with malicious intent delete an entire data volume, but they also could manipulate data through these access points.
Containers versus virtual machines
Although container use is exploding, another tool commonly used by application developers is the virtual machine (VM). VMs provides various benefits—for example, they’re persistent by default. VM managers include software, firmware, and hardware for their own unique instance of the OS, making the VM gigabytes in size. As a result, VMs do not deploy quickly and are not easy to move through development pipelines.
However, VMs do remain relevant because they let you consolidate applications onto a single system, enabling cost savings through a reduced footprint, faster server provisioning, and improved disaster recovery. Development also benefits from this consolidation because greater utilization on larger, faster servers frees up subsequently unused servers to be repurposed for QA, development, or lab gear.
VMs and containers differ in quite a few ways. The primary difference is that containers provide a way to virtualize an OS so that multiple workloads can run on a single OS instance, whereas with VMs, the hardware is being virtualized to run multiple OS instances. Containers’ speed, agility, and portability make them yet another tool to help streamline software development.
Container storage plug-ins certainly provide a more reliable and consistent path to data persistence than VMs do. While early in their introduction initial feedback suggests storage, plug-ins are the simple method for persistent storage.
In choosing your method for achieving persistent storage, consider the advantages and disadvantages of each of these options. By fully understanding the options, organizations can prepare to address limitations and enable best practices for data persistence and performance.
I am Sunil kumar, Please do follow me here and support #devOps #trainwithshubham #github #devopscommunity #devops #cloud #devoparticles #trainwithshubham
Connect with me over linkedin : linkedin.com/in/sunilkumar2807